新晋挑战者Positron AI:AI芯片市场的新势力
最近,一家名为Positron AI的公司在AI芯片领域引起了不小的关注。他们宣布完成了超额认购的5160万美元A轮融资,加上此前的资金,今年融资总额已超过7500万美元。这笔资金将主要用于支持其第一代产品Atlas的持续部署,并加速第二代产品在2026年的推出。
Positron AI的首席执行官Mitesh Agrawal表示,公司创立的初衷是为了满足现代人工智能的需求,即以最低的单位tokens生成成本和最高内存容量运行前沿模型。他们的目标是让单个系统能够运行高达16万亿参数的模型,支持数千万个上下文长度的tokens,或是内存密集型视频生成模型。
Positron AI的诞生与成长
Positron AI由首席技术官Thomas Sohmers和首席科学家Edward Kmett于2023年共同创立,随后前Lambda首席运营官Mitesh Agrawal加入担任首席执行官,负责扩大公司的商业运营。仅仅18个月,他们就凭借1250万美元的种子资金将Atlas推向市场。在A轮融资前,他们已经成功验证了产品性能,获得了早期企业客户,并在实际部署环境中完善了产品。
目前,随着市场采纳率的不断提高和清晰的产品路线图,Positron AI正在积极开发定制的ASIC(专用集成电路),以期在AI推理领域实现更高水平的性能、功率效率和部署规模。

根据Positron AI在领英上的介绍,他们致力于为企业和研究团队提供更大的供应商自由度和更快的推理速度。他们的硬件和软件是专为生成式语言模型(LLM)和大型语言模型(LLM)全新设计的。通过更低的功耗和大幅降低的总体拥有成本(TCO),Positron AI的方案能够以高tokens率和长上下文长度为多用户提供服务,运行热门的开源LLM。此外,他们还在设计自己的ASIC,以将推理和微调功能扩展到支持训练和其他并行计算工作负载。
Positron AI团队表示,他们创立公司的目标很简单:通过提供最佳性价比和功耗比的生成式AI推理系统,让每个人都能拥有“超级智能”。他们认为,臃肿的GPU、长期的英伟达短缺、巨大的功耗和内存瓶颈正在阻碍大规模有效部署Transformer模型的能力。
“我们厌倦了眼睁睁地看着计算周期(和预算)因GPU效率低下而消失。因此,我们决定自己动手,创建了专门用于高效运行Transformer推理工作负载的方案。”Positron AI团队如此介绍他们的产品特性:
- 内存带宽利用率超过90%(而GPU约为30%)。
- 每个推理机架的功耗降低66%。
- 摆脱供应商锁定和GPU短缺的困扰。
Positron AI的第一代产品Atlas目前已上市,其第二代产品也计划于2026年推出。第二代产品将致力于最大限度地提升Terachip的内存带宽和内存容量,每个芯片最高可达2TB内存。
“借道”FPGA先行,为ASIC铺路
有意思的是,Positron AI在公司成立仅18个月后就开始向客户交付其基于FPGA(现场可编程门阵列)的LLM推理系统。今年年初,他们已向二级CSP客户交付了首批价值数百万美元的订单系统。
据Positron AI首席执行官Sohmers透露,目前还有20家潜在客户正在直接或远程评估其基于FPGA的AI设备Atlas。Positron的客户涵盖了运行本地或主机托管基础设施的企业,以及二级云服务提供商(CSP)。Sohmers补充说:“我们进行的大部分对话,尤其是关于更大规模部署的对话,都是与那些本身就是CSP的公司或提供大规模网络服务的公司进行的。”
Sohmers解释说,他们在创立Positron时,有两个关键考量:一是确保与基于英伟达的系统获得完全无缝的体验;二是避免像许多AI芯片初创公司那样,因为耗时过长、投入过多而未能及时进入市场。他指出,尽管公司正在开发自己的AI推理加速器ASIC,但其第一代和第二代Atlas系统都是基于FPGA的。
他承认FPGA在FLOPS(每秒浮点运算次数)上无法与GPU或ASIC相媲美,但它们具有其他优势。Sohmers表示,公司的设备基于Altera的Agilex-7M FPGA,并配备了32GB HBM(高带宽内存)。
Sohmers强调:“在我们完全确定产品与市场契合之前,我们不想在构建ASIC上投入大量的时间和金钱。虽然其他AI芯片公司各自都有独特的问题,但它们都存在产品与市场契合的问题,尤其是在第一代设备上。采用FPGA使我们能够进行非常快速的迭代,并在客户参与的情况下启动迭代。”
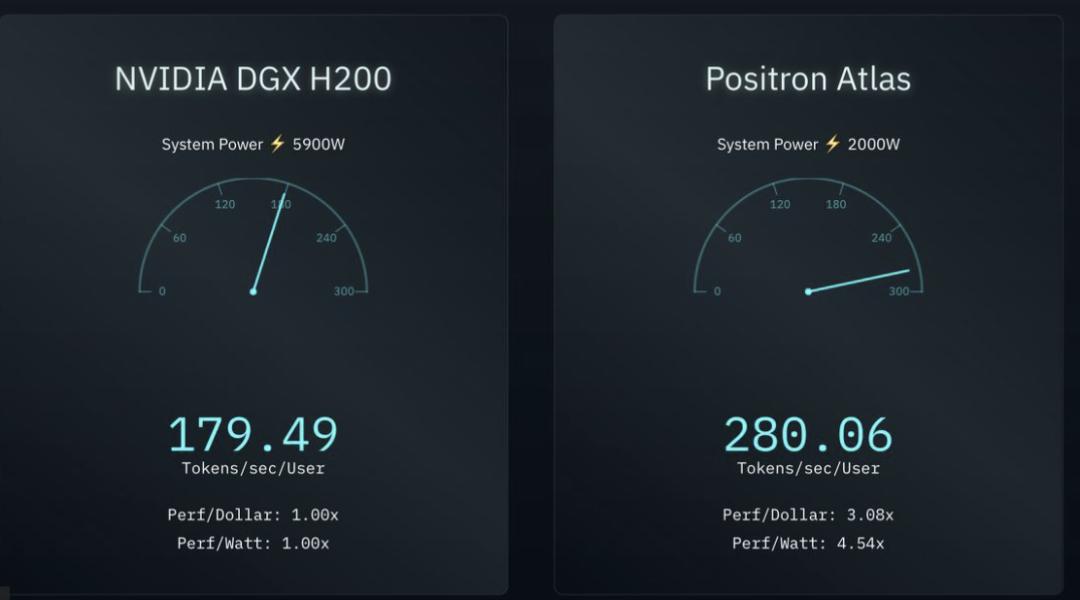
据报道,Positron AI的Atlas在2000瓦功耗下运行Llama 3.1 8B(BF16计算能力),可实现每位用户每秒约280个tokens的交付。而根据Positron AI自己的对比,在相同场景下,8路英伟达DGX H200服务器每位用户每秒仅能交付约180个tokens,同时功耗高达5900瓦。这意味着Atlas的每瓦性能和每美元性能比是英伟达DGX H200系统的三倍。当然,这个说法还需要第三方验证。
当前版本的Atlas是一个4U系统,在PCIe卡上使用了四块FPGA。它被设计为一个交钥匙设备,能够零步骤(无需重新编译)从HuggingFace或客户专有模型中提取二进制文件并运行。
下一代平台将采用Positron定制的模块尺寸(类似于英伟达SXM),将四FPGA系统缩小至2U空间,并显著扩展DDR内存。
Positron AI表示,其团队之所以能实现如此高的内存带宽利用率,关键在于其核心IP。Sohmers指出,为了最大限度地提高矩阵乘法(matmul)阵列及其连接内存的互连密度,Positron的工作层级低于Altera的Quartus工具。Positron的初始原型基于上一代搭载HBM的Stratix器件,实现了理论峰值内存带宽的65%至70%。但升级到Agilex意味着团队可以利用Altera全新的强化Fabric NoC(片上网络),该NoC旨在支持FPGA存储器之间的快速传输,而无需依赖芯片其他可编程逻辑资源所使用的通道。新的NoC拥有从HBM到可编程逻辑阵列中任意位置的SRAM块的专用路径。
瞄准未来:ASIC硬件蓄势待发
如前所述,Positron AI的下一代产品将是ASIC硬件。据了解,这款芯片将在台积电位于亚利桑那州的Fab 21工厂生产(采用N4或N5工艺技术),而且这些卡也在美国组装,使其几乎完全是美国制造。不过,由于该ASIC配备了32GB HBM内存,它采用了先进的封装技术,因此很可能是在台湾组装的。
Positron AI的Asimov AI加速器将为每个ASIC配备2 TB内存,根据该公司发布的图片,它将不再使用HBM,而是采用其他类型的内存。该ASIC还将配备16 Tb/s的外部网络带宽,以便在机架级系统中更高效地运行。Titan基于八个Asimov AI加速器,总内存为16 GB,预计能够在单台机器上运行高达16万亿个参数的模型,从而显著扩展大规模生成式AI应用的上下文限制。据Positron AI称,该系统还支持同时执行多个模型,从而消除了每个GPU只能运行一个模型的限制。

Sohmers表示:“LPDDR 5X和6能够以每GB成本的四分之一获得比HBM更高的容量。封装将采用常规的有机基板,这将大幅降低产品成本。”
他进一步指出,虽然LPDDR的速度不如HBM,但通过使用Positron的IP来接近理论峰值内存带宽,足以弥补这一缺陷。Positron还可以直接控制DDR上的内存刷新,这使得该公司能够比HBM更接近理论峰值性能,同时避免了HBM带来的功耗或成本开销。
尽管AI芯片市场的竞争日益激烈,分析师警告称,仅仅提高芯片效率可能不足以应对AI工作负载的爆炸式增长,因为历史经验表明,硬件性能的提升很快就会被新的用例和日益强大的模型所消耗。然而,凭借新的资金、主要客户的关注以及高度专注的设计,Positron AI已将自己定位在关于AI基础设施未来的关键辩论中心。他们(或其任何竞争对手)能否兑现承诺,将决定未来几年世界如何构建、驱动和支付AI的费用。